雪花算法(Snowflake)原理分析
1、概念
雪花算法(Snowflake)是一种生成分布式全局唯一ID的算法,生成的ID称为Snowflake IDs或snowflakes。这种算法由Twitter创建,并用于推文的ID
雪花算法几个特性
- 生成的ID分布式唯一和按照时间递增有序,毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等三方系统,稳定性更高,性能非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
2、snowflake算法实现细节
2.1、拆解64bit位
snowflake生成的id通常是一个64bit数字,java中用long类型。
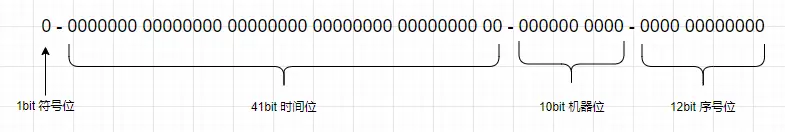
1、1bit-不用,因为二进制中最高位是符号位,1表示负数,0表示正数,生成的id一般都是用整数,所以最高位固定为0.
2、41bit-用来记录时间戳(毫秒).41位可以表示2^41−1个数字,如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 2^41-1,减1是因为可表示的数值范围是从0开始算的,而不是1。也就是说41位可以表示2^41-1个毫秒的值,转化成单位年则是:(2^41−1)/(1000∗60∗60∗24∗365)=69年 ,也就是说这个时间戳可以使用69年不重复(69年后换个服务器部署)
3、10bit-用来记录工作机器id。可以部署在2^10=1024个节点,包括5位datacenterId和5位workerId,可以部署在2^10=1024个节点
4、12bit-序列号,用来记录同毫秒内产生的不同id。12位(bit)可以表示的最大正整数是2^12−1=4095,即可以用0、1、2、3、….4095这4096个数字,来表示同一机器同一时间截(毫秒)内产生的4096个ID序号
同一毫秒的ID数量 = 1024 X 4096 = 4194304,所以最大可以支持单应用差不多四百万的并发量,这个妥妥的够用了
3、使用
3.1、引入依赖
1 | <dependency> |
3.2、在配置文件中配置雪花算法参数
1 | snowflake: |
3.3、注入SnowflakeIdWorker
使用snowflakeIdWorker.nextId()方法既可以获取生成的雪花ID。
1 |
|
4、几个问题
4.1、时钟倒拨问题
时间倒拨,也就是跑了一段时间之后,系统时间回到过去。显然,时间戳上有很大几率产生相同毫秒数,在机器码workerId相同的情况下,有较大几率出现重复雪花Id。原标准实现代码中是直接抛异常,短暂停止对外服务,这样在实际生产中是无法忍受的。所以要尽量避免时钟回拨带来的影响,解决思路就是不依赖机器时钟驱动,就没时钟回拨的事儿了。即定义一个初始时间戳,在初始时间戳上自增,不跟随机器时钟增加。时间戳何时自增?当序列号增加到最大时,此时时间戳+1,这样完全不会浪费序列号,适合流量较大的场景,如果流量较小,可能出现时间断层滞后。
1 | private long sequence = -1L; |
起始时间可以构造器里指定,也可以用默认的,而sequence初始为-1,是为了不想浪费sequence+1=0这一序列号。
sequence = 0排除掉初始sequence=-1 +1 = 0的情况就是sequence超过最大值了,此时时间戳startTimestamp自增。
代码和思路都很简单,就是完全脱离机器时钟,彻底解决了时钟回拨问题。显而易见的优点,每一毫秒4096个序列号([0,4095])没有浪费,同时因为时间自增由程序自己掌控,所以可以利用未来时间,预先生成一些ID放在缓存里,外界从缓存中直接获取ID,快消费完了再生产,这样就形成了永动的生产-消费者模式,获取ID省去了生成的过程,性能也会大大提升。
但是时间戳完全自控,也有很明显的缺点,ID生成的时间,并不是真实的时间,如果流量较小,时间可能会滞后很多。如果对从ID解析出来的时间戳没有什么利用意义,这个缺点也不需要关心
4.2、机器ID重复的问题
机器 ID(5 位)和数据中心 ID(5 位)配置没有解决,分布式部署的时候会使用相同的配置,仍然有 ID 重复的风险。如果是在单节点中,这种固定的配置没有问题的,但是在分布式部署中,需要由dataCenterID和workerID组成唯一的机器码,否则在同毫秒内,在机器码workerId相同的情况下,有较大几率出现重复雪花Id。那么这个时候,dataCenterID和workerID的配置就不能写死。而且必须保证唯一。解决思路可以考虑redis保证workid不容。工作机器id:10bit,表示工作机器id,用于处理分布式部署id不重复问题,可支持2^10 = 1024个节点,我们只需要给同一个微服务分配不同的工作机器ID即可,在redis中存储一个当前workerId的最大值。每次生成workerId时,从redis中获取到当前workerId最大值,并+1作为当前workerId,并存入redis。如果workerId为1023,自增为1024,则重置0,作为当前workerId,并存入redis。